
最近、世間を賑わせているAI、ChatGPTという言葉を耳にされたことがあるでしょうか。自由に会話ができることで知られるOpenAI社が開発したAIの名前です。大量のテキストデータを学習し、その学習結果をもとに文章を生成したり、自然言語処理のタスクを解決することができます。このChatGPTは、大規模言語モデルの一つです。大規模言語モデルとは、一体何なのでしょうか?そして、カスタマーサポートの未来にどのような影響を与えるのでしょうか?
「言語モデル」とは何か?
大規模言語モデルの話をする前に、まずは「言語モデル」について解説します。言語モデルとは、与えられた単語列の続きを予測するAIのことです。例えば、「今年一番うれしかったことは、チームでの」という単語の列を入力すると、次に続く単語を予測することができます。

その中で最も可能性が高いと判定された単語を、次に続く単語として連結することで文を綴ります。この処理を繰り返すことで、より長い文章の生成が可能となります。

※ 「続き」ではなく「途中の穴抜き」を埋める(予測する)バージョンもあります(マスク言語モデル)
言語モデルの発展
言語モデルという概念は、ディープラーニングが登場するよりも前から存在し、古典的な手法で様々な試みがなされてきました。しかし、それでも一定の文章品質を実現することは難しかったと言われています。2010年代中期に入るとディープラーニングの登場により、より高品質な文章生成が可能になりました。2019年に入ると大規模な言語モデルが登場しました。何をもって大規模かというと、学習データ量やモデルの規模が非常に大きいことが特徴です。ただし、明確な線引きは存在しません。
| 2010年代中期 | 2018年 | 2019年〜 | |
|---|---|---|---|
| 古典的手法 (マルコフ連鎖、スキップグラム…etc) | 深層学習技術 Deep Learning (LSTM、単語埋込…etc) | BERT | 大規模言語モデル (LLM) |
| 数単語先まで行くと文が破綻する。教師データに含まれる単語しか話せない。 | 十分な学習用文書データがあれば、破綻のない文が生成可能に。類義語も話せる。 | 事前学習(pre-training)により、必要な学習データ量が減少。 | 膨大すぎるデータを事前学習した結果、学習データがほぼ不要で(プロンプトのみで)汎用用途に使えるように。 |
大規模言語モデルの発展
特に最近の3年間は、大規模言語モデルの進歩が目覚ましく、注目されています。
2019年、OpenAIはGPT-2(Generative Pre-trained Transformer 2)を発表し、自然言語処理技術の分野で話題となりました。GPT-2は、大量のテキストデータを用いて事前訓練され、文章生成や質問応答などのタスクにおいて、驚異的な性能を発揮しました。また、多様な文章生成に成功し、例えば小説の続きを書くなどの応用も可能であることが示されました。
その後、GPT-3が発表され、自然言語処理技術の分野において、大きな注目を集めました。GPT-3は、GPT-2よりも大規模なデータセットで訓練され、最大1,750億のパラメーターを持つ、より高度な言語モデルとなっています。GPT-3は、文章生成、文章の要約、翻訳、質問応答などのタスクにおいて、高い性能を発揮しました。
さらに大規模言語モデルの進化は続き、2022年には、OpenAIがGPT-3.5という新しいモデルを発表しました。GPT-3.5は、GPT-3よりも大規模なデータセットで訓練された言語モデルとなっています。GPT-3.5は、文章生成、翻訳、対話などのタスクにおいて、驚異的な性能を発揮することが期待されています。
そして、2023年に最新モデルであるGPT-4が登場。大規模言語モデルの発展は、継続的に進化を続けており、自然言語処理技術の分野において、ますます高度な応用が可能になっていると言えます。
| 2019年 | 2020年 | 2022年11月30日 | 2023年3月15 | |
|---|---|---|---|---|
| モデル | GPT-2 | GPT-3 | GPT-3.5 (InstructGPT/ 最初のChatGPT) | GPT-4 |
| 学習データ量 | 40GB | 45TB | 45TB+α | (不明) |
| パラメータ数 | 15億 | 1,750億 | 3,550億 | (不明) |
| 追加学習なしに、プロンプトのみで様々なタスクが解ける可能性が示唆された。 | 膨大すぎるデータを事前学習した結果、学習データがほぼ不要で(プロンプトのみで)汎用用途に使えるように。 | 強化学習を用いて、人間が好ましいと感じる出力を生成できるようにGPT-3を改良。 | テキストに加えて画像も含んだデータセットを学習。GPT-3.5と比較して精度が大幅に向上し、人間向けの様々な試験で人間並みのスコアに到達。画像も入力可能。 |
大規模言語モデル「以前」と「以後」で何が変わったのか?
大規模言語モデル以前
大規模言語モデルが登場する前の対話AIは、モデルを作る必要がありました。たとえば、何かしらの対話AIを作る場合、対話に特化したモデルではないため、対話に特化するための学習が必要でした(fine-tune)。
対話を学習するためには、データを整備する必要があります。「コンビニに行ってくる」という会話に対して、適切な回答は「行ってらっしゃい」。「19時に帰るね」に対して、適切な回答は「オッケー」であるといった「教師データセット」を作る必要がありました。その後、対話AIを作るための学習を行い、はじめてAIとの対話が可能となります。

大規模言語モデル以降
大規模言語モデルが登場してからは、言語モデルの「次に来る単語を予測する機能」をそのまま使用することで、学習が不要になりました。そのため、「プロンプト」と呼ばれる指示文を上手に与えることで、学習なしでも対話AIになることができるようになりました。

このようなことができるのは、大規模言語モデルの学習データ量とモデルサイズが膨大であるためです。そのため、追加学習を行わなくても、ほぼあらゆる形式の文書において、続きの補完が可能になりました。
大規模言語モデル=お化け?キーワードは「プロンプト」
人工知能(AI)を使用して、ユーザーに自然なやり取りで情報を提供する方法の設計手法を「プロンプト・エンジニアリング」と言います。この手法では、AIが特定の目的を達成するために必要な情報を正確かつ迅速に取得できるように、ユーザーとの対話に特化したプロンプトを作成します。
この「プロンプト・エンジニアリング」によって、大規模言語モデルは何にでも”化ける”ことができるのです。
例1.多言語への翻訳※1
以下の文章を 1. フランス語, 2. スペイン語, 3. 日本語 に翻訳してください:
What rooms do you have available?
1.

Quels sont les chambres que vous avez disponibles?
- ¿Qué habitaciones tienes disponibles?
- どの部屋が利用可能ですか?
※1…https://beta.openai.com/examples/default-translate の日本語訳
例2.感情分析
以下のツイートの感情がポジティブかネガティブかを分類してください。
- 「宿題やってられるか」
- 「クソつまんね😠」
- 「ハロウィンが待ちきれない!」
- 「ねこかわいい❤️❤️」
- 「チョコレートは苦手…」
ツイートの感情分析結果:
- ネガティブ
- ネガティブ
- ポジティブ
- ポジティブ
- ネガティブ
例3.同義文(同じ意味で異なる言い回しの文)の生成
人間:話したいことがあるんだ
AI:はい,何でしょうか?
人間:「ログインできない」と似たような意味の文章を5個考えてください
AI:
- ログインできません
- システムにログインができない
- ログインエラーが出る
- ログイン時にエラーが表示される
- ログインに失敗する
これは「KARAKURI chatbot」の質問パターンを自動生成する機能(β版)として実用化されています。これにより、チャットボットの導入時の構築期間の短縮や日々の運用工数の削減が可能です。
このように大規模言語モデルはプロンプトの与え方によって、何にでも化けることができます。
InstructGPTとChatGPTの登場
AIが自然言語処理を行う際には、人間とのコミュニケーションにおける倫理的な問題も生じます。例えば、機密情報の漏洩や人種差別的な表現など、AIが生成する文章には様々な懸念があります。その問題を解決したモデルが「InstructGPT」です。
InstructGPTとは、強化学習※2を用いて、人間が好ましいと感じる出力を生成できるように、大規模言語モデル「GPT-3」を改良したものです。GPT-3の出力には、有害な内容や無関係な話題の言及(ハルシネーション)、ナンセンスな繰り返しなどが見られましたが、InstructGPTではこれらを極力避けるように、強化学習が施されています。
そして、InstructGPTをベースにして、適切なプロンプトを与えることで、チャットサービスに適したモデルに変換されたのが「ChatGPT」です。
※2…フィードバックとして与えられる報酬信号が最大となるように行動を最適化していく学習形式
2023年3月、さらに高性能なGPT-4が登場
ChatGPTの登場から数ヶ月後、さらに高性能なモデル「GPT-4」が登場しました。GPT-4は、画像やテキストを入力として受け取り、テキストを出力する大規模なマルチモーダルモデル※3です。どれくらい性能が高いのかと言うと、模擬的な司法試験において、テスト受験者の上位10%程度のスコアを取得するなど、様々な専門分野の試験において、人間レベル(しかも上位相当)のパフォーマンスを発揮します。下位10%程度のスコアに留まるGPT-3.5と比較すると、その差は明らかです。
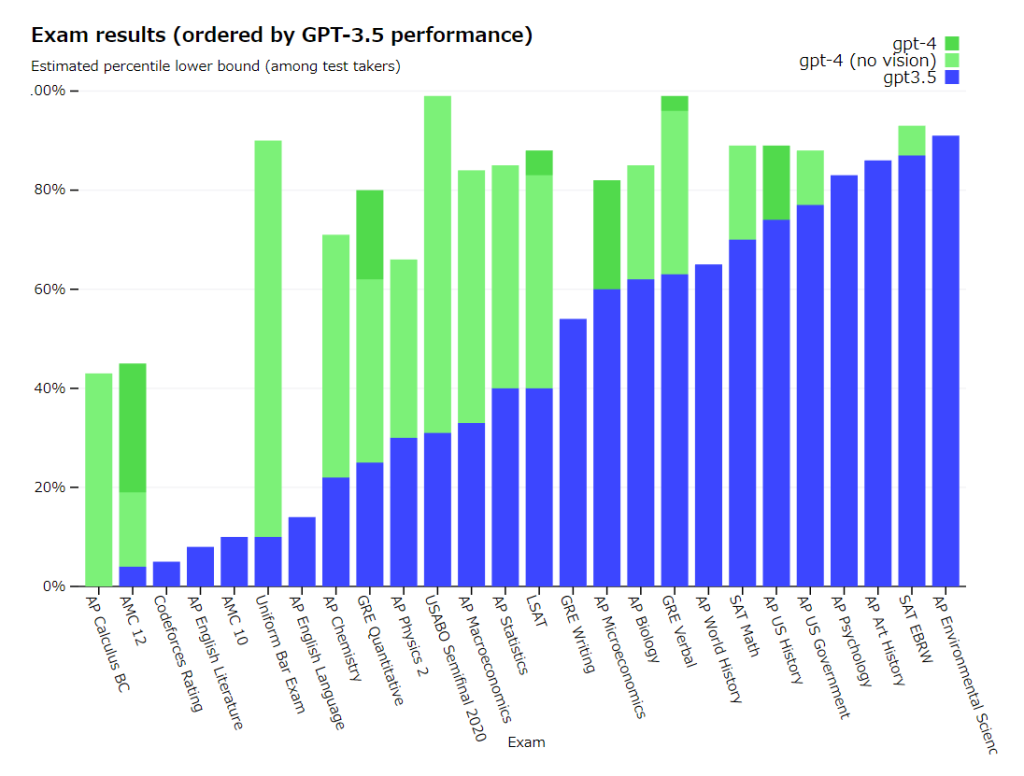
※3…複数の異なる入力形式(モダリティ)から情報を収集し、それらを統合して処理する機械学習モデルのこと
大規模言語モデルにも限界がある
ここまで解説してきた通り、近年、大規模言語モデルは飛躍的な発展を遂げ、学習なしでも広範囲のタスクを人間並みにこなすことが可能になってきました。しかしながら、大規模言語モデルにも限界があります。
大規模言語モデルは事実に基づいて回答するとは限らない
ある弊社社員が、豚の角煮を作るためにChatGPTにレシピを質問しました。するとChatGPTは、醤油150mlとみりん150mlを使用するように回答しました。しかし、ある程度の料理経験がある人であれば、このレシピが誤っていることに気づくでしょう。料理にうとい社員は、このレシピ通りに作り、大失敗してしまいました(弊社では”豚の角煮事件”と呼んでいます)。
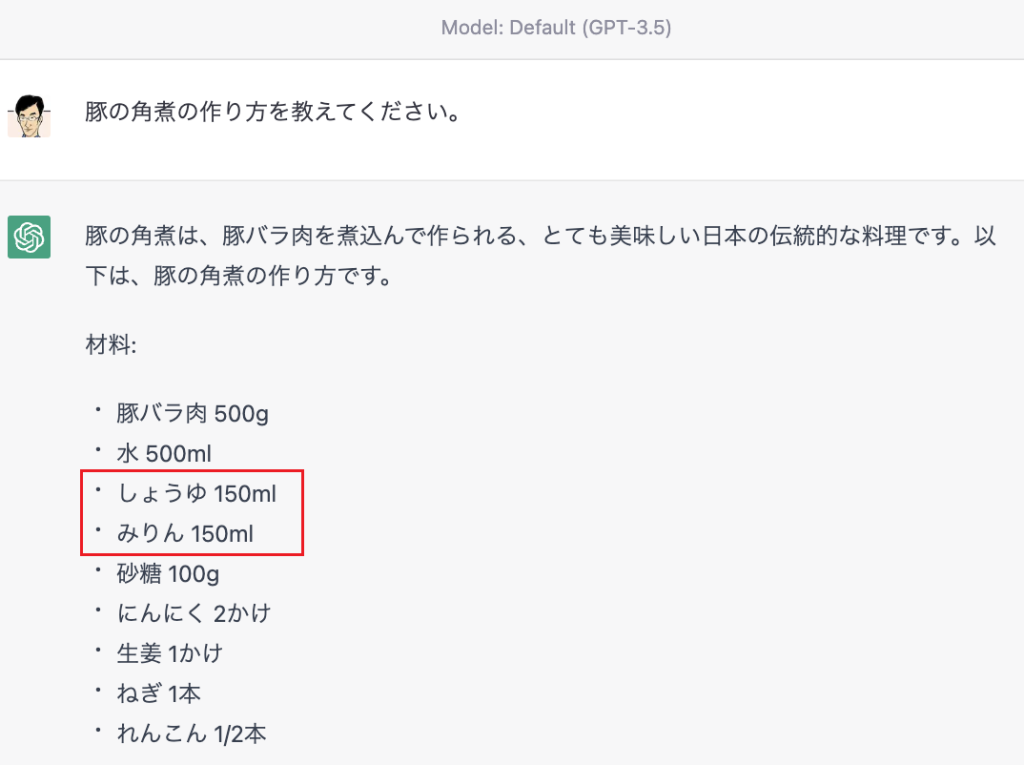
この出来事は、大規模言語モデルには限界があることを示しています。大規模言語モデルは、人間の知識や経験を再現することができますが、完璧ではありません。特に、料理のように創造性や感覚的な判断力が必要な場合には、大規模言語モデルだけで完結することはできません。根本原理は「文章の続きを予測する」でしかないのです。
大規模言語モデルの弱点(2023年3月時点)
- 正確さに保証はない
- ロジカルな推論は(比較的)苦手
- 学習時のデータセット(=WEB上の膨大なページ)を全部は覚えていないし、それに含まれていない最新の内容はシンプルに知らない
ただし、回答の質は今後も改善されていくことが期待されています。特に、モデルや学習データのさらなる大規模化や、学習方法のさらなる洗練により、より高度な自然言語処理が可能になると考えられています。
また、ウェブ検索などと組み合わせることで、より正確かつ適切な回答が得られるようになると予想されています。例えば、Bing AIは、検索結果のページから直接回答を抽出することができるようになっています。また、情報の出典を併記するなどの工夫も、回答の信頼性を高めるために重要です。
大規模言語モデルは責任を取れない
前記の”豚の角煮事件”のように、事実と異なる回答をしていたとしても、大規模言語モデルは人間と異なり、責任が取れません。しかし、対応策が無いわけではありません。
例えば、大規模言語モデルの出力結果をそのまま使用するのではなく、後処理やフィルターを行った結果をシステムの出力として採用することで、出力が想定範囲内に収まるように保証することができます。特に、サポートチャットボットなどのコミュニケーションに使用される場合には、このような制限が有効です。
また、AIの使用者自身にも責任を負ってもらうことが重要です。大規模言語モデルの出力結果が妥当かどうかを評価することができるように、使用者の適切な教育やトレーニングが必要です。また、AIは自然な嘘をつくことが上手であるため、使用者は常に回答内容を慎重に検討し、それが妥当であるかどうかを判断する必要があります。
大規模言語モデルはエスパーではない
大規模言語モデルを活用するには、大規模言語モデルに適切なプロンプトを与える必要があります。そのためには、ドメイン知識やタスク内容の詳細、実際に業務にあたる際の思考手順などを明確にする必要があります。また、前提知識や非言語的なノウハウを言語で表現できる能力が、適切なプロンプトを与えることに繋がるため、今後ますます重要になるでしょう。
大規模言語モデルはカスタマーサポートをどう変えるか?
ここまで大規模言語モデルについて解説してきましたが、大規模言語はカスタマーサポートの未来にどのような影響を与えるのでしょうか?キーワードは「エンパワーメント」です。
エンパワーメントとは「権限委譲」という意味の他に、「自信を与えること、力を付けてやること」という意味があります。まさに大規模言語モデルは、アイデア出しやブレストなど、作業者自身をパワーアップさせるようなこと(エンパワーメント)に使うと相性が良いとされています。
エンパワーメントの具体例
以下は、とあるスマートフォン製品のQ&Aについて、Q(Question)にあたる文章の改良版をChatGPTに考えるよう指示したものです。元のQは「バッテリーがすぐに切れてしまう」ですが、ChatGPTが提示した改良版では「バッテリーがすぐに切れる原因と対策は?」となっており、プロンプトの要求通り、回答の内容がイメージできるものになっています。

コールセンターシステムもエンパワーメント
大規模言語モデルの登場により、カスタマーサポートに関するシステムの様々な場面でAIの活用が加速するでしょう。これまでは、AIを個別に開発し育成する必要がありましたが、大規模言語モデルの登場により、学習不要であらゆるタスクに対応できるようになり、必要な機能を素早く開発することができるようになるからです。これにより、あらゆる業務でAIを活用することが可能となり、さらなるエンパワーメントを実現できます。
まとめ
- 大規模言語モデルはこの数年で加速度的に発展してきた
- 学習無しで汎用性を備え、人間並みの推論が可能になった
- 大規模言語モデルは業務をエンパワーメントする
- カスタマーサポートのあらゆる業務を「AIとの協働」にするプロダクトが今後発展する
- 大規模言語モデルはエスパーではない
- 業務上の暗黙知を言語化できることが,大規模言語モデルのプロダクトを活用するカギとなる

